Building a SaaS Service for an Unknown Scale: Part 1
Last summer, I spoke at the Seattle AWS Architects & Engineers Meetup. It was a great opportunity to share some of the knowledge I have gained over the years of building SaaS products, and I was thrilled that the presentation was very well received. Looking back at the questions people asked and the feedback I got, I realized that the AWS community is hungry for more knowledge sharing around building scalability and reliability into SaaS offerings.
Scalability means something quite different in a SaaS environment than for traditional, behind-the-firewall software. Prasad Jogalekar and Murray Woodside’s definition of SaaS scalability from their IEEE paper Evaluating the Scalability of Distributed Systems is the one I like the most:
“Scalability means not just the ability to operate, but to operate efficiently and with adequate quality of service, over the given range of configurations.”
At Loggly, we treat scalability and reliability as product features; this is the only way we can build a world-class SaaS application for unknown scale. In order to be ready for any level of growth (which, of course, translates to business success), SaaS systems need to be able to grow capacity on the back end to match customer demand without any changes to the architecture of the application. Another key aspect of scalability and reliability is being able to roll fixes and releases in a very simple and fast manner; this requires investment in operations automation.
I believe that the following six issues must first be addressed in order to make your SaaS offering both scalable and reliable:
- The right architecture, and that doesn’t just mean multitenant
- Metrics and action APIs
- A solution that accounts for unpredictable loads or behavior
- An assumption that data corruption will happen, whether through human fault, machine fault, or software bugs
- The ability to increase capacity on demand
- The ability to roll out fixes, patches, and releases with one click
I’ll cover the first two points in this article and will finish up with a second post later this month.
For each point, I’ll illustrate concepts with an example of a typical data processing application. Many constructs are taken from the Loggly service, but the example does not replicate the Loggly architecture. It is a data processing application that can process data from any source; it can just as easily be a social analytics application that is bringing in data from the Twitter firehose, Facebook, or LinkedIn. The example application has the following components:
- Web application: the web application with which the user interacts
- Data collection pod: a component that is responsible for collecting and persisting data into messaging systems.
- Messaging system: a messaging layer that enables the application to persist data when it flows through the data processing pipeline.
- Processing pipeline: the part of the pipeline that processes the data.
- Data store: a store where the processed data get persisted.
Best Practice #1: The Right Architecture Goes Beyond Multitenant
Pick up any technical article on SaaS applications, and you’ll get some opinion about what the right architecture is. But most of them equate the right architecture to a multitenant architecture. In my view, multitenant is important but not enough. The right SaaS architecture consists of components that are all stateless. If you have a data pipeline, it should have the ability to process the data using lanes. (I’ll share details on what I have started calling a “lane architecture” in Part 2 of this series.) The SaaS application should also have service governors. (To learn more about what a service governor is, check out Mistake #3 in my previous post, “Six Critical SaaS Engineering Mistakes.”)
Best Practice #2: Build Metrics and Action APIs
You should expose at least two kinds of APIs for every single component in your technology stack. When I say expose, I don’t necessarily mean that it has to be available as a public API. It can be accessible only to your development, DevOps, and data science teams for their learning and optimization work.
Your Metrics API
This API provides the stats for the component in your service. For example, it could provide input bytes received per second (bps), processed bytes per second, transactions per second, a list of the top 10, 20, or 50 customers based on received bps, etc. Of course, these are just examples: The metrics that your API delivers should reflect your application’s functionality.
Some of the key benefits of a metrics API are:
- You can store metrics data in your data warehouse for analysis. In my view, this data is gold when it comes to making product enhancements.
- You can use these metrics to enable auto-scaling and auto-shrinking of servers.
- You can use component metrics to analyze customer use, behavior, and patterns.
- You can trigger alerts to notify you of potential performance or scaling issues based on changes to your metrics.
- You can give your NOC team a practical way to build dashboards that keep them on top of your application’s health.
Your Action API
Action APIs change the behavior of a component in your application without requiring you to make a code change. These APIs help you:
- Create temporary workarounds that modify the behavior of a component so that it can continue operating while you make fixes behind the scenes
- Debug components by turning on and off certain behaviors
- Deliver differentiated service (e.g., capacity, priority, etc.) to customers with whom you have higher SLAs
- Dedicate certain resources or complete components to a customer or set of customers to offer them better SLAs
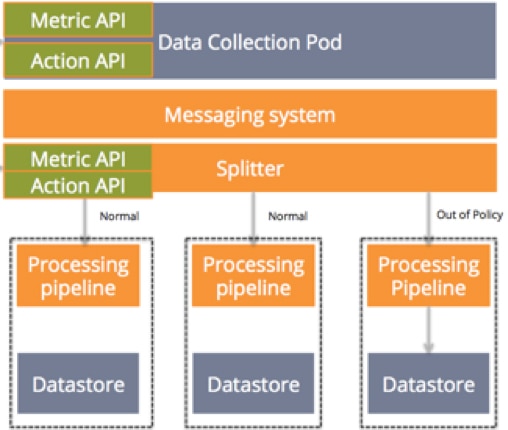
The diagram below illustrates our example data processing application with metrics and action APIs. So now our components look like:
- Web application: the web application with which the user interacts
- Data collection pod: the component responsible for collecting data. The metrics API on the data collection pod can provide the various metrics like the ones mentioned above.
- Splitter: This component splits data to process data in various lanes, enabling data to move in the same way that cars move on a multilane freeway. If there is an accident in the right lane, traffic continues to flow around it. Contrast this with a transit service like BART, which must stop all trains if a lane is blocked. The behavior of which data goes to which lane is controlled by the action API.
In the next post of this series, we’ll be looking at how to put these two APIs into action. We’ll be covering unpredictable loads, data corruption, adding capacity, and rolling out new code.
Keep Reading: Go to Part 2 »
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Manoj Chaudhary